Standard Metrics for LDA Model Comparison

Topic Modelling is used to extract topics from a collection of documents.The topics are fundamentally a cluster of similar words. This help in the understanding of hidden semantic structure between words of a large number of the extensive texts at an aggregate level. Perplexity and Coherence Score are used as metrics for assessing the quality of the learned topics.
-
Perplexity: is a statistical measure of how well a probability model predicts a sample. This is calculated by splitting the dataset into two, train and test documents.
A test set is a collection of unseen documents wd. We evaluate the log likelihood as follows:
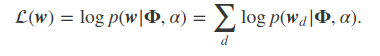
where
Φ = topic matrix
wd = unseen document
α = alpha parameter (topic distribution of documents)
That is, log-likelihood of a set of unseen documents wd given the topics Φ.
Therefore, higher likelihood implies a better model.
-
Coherence Score: is used for assessing the quality of the learned topics.
Intuition: topic is good if the word constituting the topic co-occur together
The score is used for deciding the required number of topics in the model.
For a topic t characterized by a set of top words WT
Coherence is defined as :
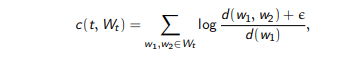
where
d(w1) = the number of documents that contain word w1
d(w1,w2) = the number of documents that contain words w1 AND w2 (co- occur together)
ε = smoothing count set to 1 or 0.01.
Drawback: Coherence cannot distinguish between high-frequency words and informative words.
References