Term Frequency - Inverse Document Frequency
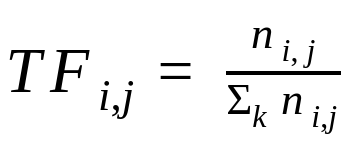
TF-IDF : is an information retrieval technique that weighs a term’s frequency (TF) and its inverse document frequency (IDF). Each word or term has its respective TF and IDF score. The product of the TF and IDF scores of a term is called the TF*IDF weight of that term.
Term Frequency (TF) : is the ratio of the number of times a word appear in the document to the total number of words in the documents.
Inverse Data Frequency (IDF) : assigns higher weightage to the rare words in the text corpus.
It is defined as the log of the ratio of number of documents to number of documents in which a particular words.
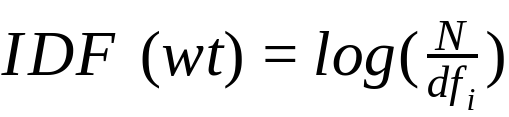
IDF Smoothing : is done to makes sure the terms with zero IDF don’t get suppressed entirely.
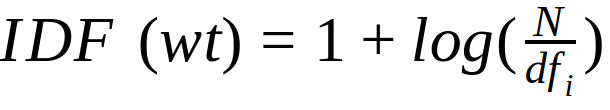
TF-IDF score : is the product of the Term Frequency and Inverse Data Frequency.
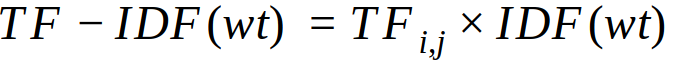
TF-IDF Implementation Code:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
import pandas as pd
from sklearn.feature_extraction.text import CountVectorizer, TfidfVectorizer
s1="The cat sat on my face"
s2="The dog sat on my bed"
#without smooth IDF
print("Without Smoothing:")
#define tf-idf
tf_idf_vec = TfidfVectorizer(use_idf=True,
norm=None,
smooth_idf=False,
sublinear_tf=False,
binary=False,
max_features=None,
strip_accents='unicode',
ngram_range=(1,1), preprocessor=None,stop_words=None, tokenizer=None, vocabulary=None)
#transform
tf_idf_data = tf_idf_vec.fit_transform([s1,s2])
#create dataframe
tf_idf_dataframe=pd.DataFrame(tf_idf_data.toarray(),columns=tf_idf_vec.get_feature_names())
print(tf_idf_dataframe)
print("\n")
#with smooth
tf_idf_vec_smooth = TfidfVectorizer(use_idf=True,
norm=None,
smooth_idf=True,
sublinear_tf=False,
binary=False,
max_features=None,
strip_accents='unicode',
ngram_range=(1,1), preprocessor=None,stop_words=None, tokenizer=None, vocabulary=None)
tf_idf_data_smooth = tf_idf_vec_smooth.fit_transform([s1,s2])
print("With Smoothing:")
tf_idf_dataframe_smooth=pd.DataFrame(tf_idf_data_smooth.toarray(),columns=tf_idf_vec_smooth.get_feature_names())
print(tf_idf_dataframe_smooth)
Output:
Without Smoothing:
bed cat dog face my on sat the
-- ------- ------- ------- ------- ---- ---- ----- -----
0 0 1.69315 0 1.69315 1 1 1 1
1 1.69315 0 1.69315 0 1 1 1 1
With Smoothing:
bed cat dog face my on sat the
-- ------- ------- ------- ------- ---- ---- ----- -----
0 0 1.40547 0 1.40547 1 1 1 1
1 1.40547 0 1.40547 0 1 1 1 1